¿Qué es hugging face?
¿Qué es?
Hugging Face, es una plataforma open source de ciencia de datos y machine learning. Actúa como un repositorio para expertos y entusiastas del AI, como un GitHub para AI
Como usar los modelos
- Escogue un modelo aqui
- puedes usars sus filtros como
Taskque son los modelos existentes Librariesson las librerias compatibles el mas sencillo de usar esTransformers
- puedes usars sus filtros como
- Una vez que es tienes el modelo copiar el nombre del modelo
 En este caso es
En este caso es google-t5/t5-base
Usar en web
Puedes usarlo con la libreria npm para poder usar el modelo.
En la documentación estara la forma de usar el modelo, en el ejemplo de hugging face es de tradución asi que se hara de esta forma
// importas hf
import { HfInference } from '@huggingface/inference'
// aqui es tu access token desde hf muy parecido a gitlab o github
const hf = new HfInference('your access token')
// y llamar el metodo especifico para cada caso
await hf.translation({
model: 'google-t5/t5-base',
inputs: 'My name is Wolfgang and I live in Berlin'
})
- Hay que tener en cuenta que algunos modelos tienen configuraciones distintas que indicara en el repositorio
- Si el modelo pesa mas de 10GB no podras hacr la peticion desde web
Usar en python
En caso de querer probar un modelo sin necesidad de usar tu computadora, puedes usar Colab que gratuitamente te presta un maquina con python instalado
aqui puedes crear tu codigo por partes y probar de manera sencilla el codigo que te da en la misma pagina de HF presionando use this model
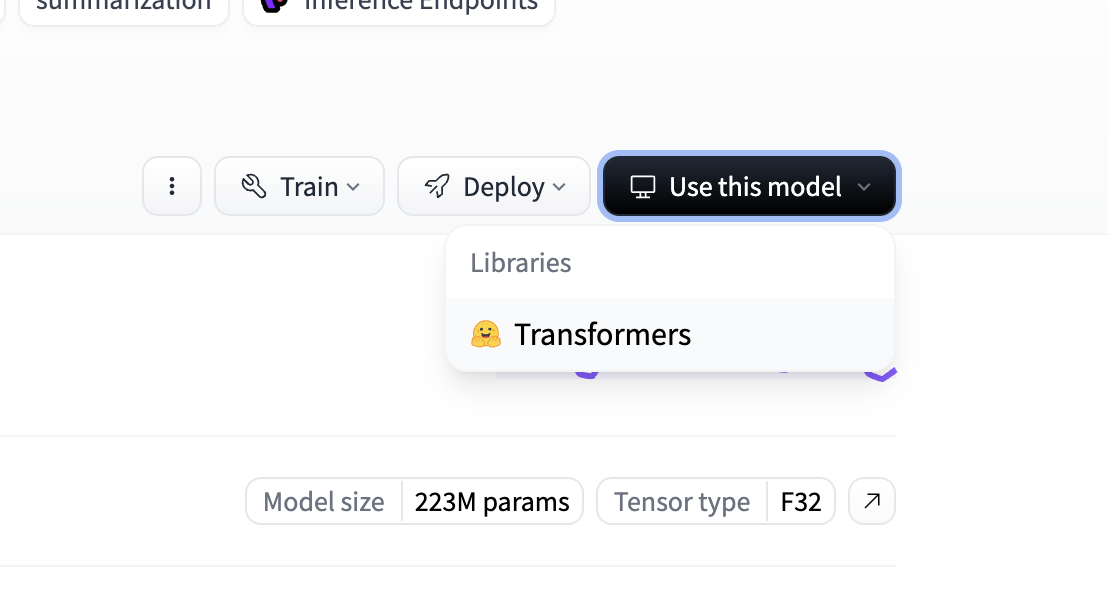
y a veces existe dos formas de usarlo
Alto nivel que es usando el un pipeline que viene por HF
ejemplo
from transformers import pipeline
pipe = pipeline("translation_es_to_en", model="google-t5/t5-base")
result = pipe("Hola, ¿como estas?")
print(result)
Usando el modelo completo
se descarga completo para poder usar ese modelo directamente o configurarlo diferente.
# Load model directly
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-base")